Limpiar Dataframe Python
En el vasto mundo del análisis de datos con Python, la limpieza de DataFrames es una tarea fundamental que puede marcar la diferencia entre resultados precisos y conclusiones erróneas.
En este tutorial detallado, exploraremos a fondo cómo limpiar DataFrames en Python, utilizando la potencia de la biblioteca Pandas.
Desde la eliminación de valores nulos hasta la manipulación de columnas y la gestión de índices, abordaremos cada aspecto de este proceso esencial para garantizar que tus datos estén en su mejor forma antes de comenzar el análisis.
Limpiar DataFrame Python: Guía Tutorial
En el fascinante mundo del análisis de datos con Python, la limpieza de DataFrames emerge como una tarea esencial que puede diferenciar entre resultados precisos y conclusiones engañosas.
Aquí, nos sumergiremos en el núcleo de esta práctica, aprovechando la robusta biblioteca Pandas para garantizar la integridad y fiabilidad de nuestros datos antes de cualquier análisis profundo.
1. Preparación Inicial
Antes de sumergirnos en la limpieza de DataFrames, es esencial asegurarnos de que nuestro entorno de Python esté debidamente configurado.
Esto implica no solo tener instaladas las últimas versiones de Python y Pandas, sino también considerar otras bibliotecas complementarias que puedan ser útiles durante el proceso de limpieza y análisis de datos.
Algunas de estas bibliotecas incluyen NumPy para operaciones numéricas eficientes, Matplotlib y Seaborn para visualización de datos, y Scikit-learn para tareas de aprendizaje automático.
Además, es importante tener una comprensión sólida de los conceptos básicos de la programación en Python, así como una comprensión general de cómo funcionan los DataFrames en Pandas.
Si eres nuevo en Python o en el análisis de datos con Pandas, puede ser útil revisar tutoriales y recursos en línea que cubran estos temas antes de embarcarte en la limpieza de DataFrames.
Una vez que te sientas cómodo con el entorno y las herramientas que vas a utilizar, es recomendable establecer un flujo de trabajo organizado.
Esto puede implicar crear un directorio de proyectos dedicado para tu análisis de datos, donde puedas almacenar tanto tus datos como tus scripts de Python de manera ordenada y estructurada.
Además, considera utilizar un sistema de control de versiones como Git para realizar un seguimiento de los cambios en tu código y colaborar con otros en proyectos de análisis de datos más grandes.
2. Importación de Datos
La importación de datos es el primer paso crítico en cualquier análisis de datos.
Con Pandas, esta tarea se vuelve sencilla gracias al método pd.read_csv(), que nos permite cargar datos desde archivos CSV u otros formatos de archivo compatibles con Pandas.
Sin embargo, es importante comprender algunas consideraciones clave al importar datos.
En primer lugar, es fundamental comprender la estructura de tus datos y cómo están organizados en el archivo que estás importando.
Esto incluye conocer el delimitador utilizado (por ejemplo, coma, tabulación), si hay encabezados de columna y cómo se manejan los valores faltantes.
Además, es posible que necesites realizar algunas transformaciones en tus datos durante el proceso de importación.
Por ejemplo, puedes querer especificar el tipo de datos de cada columna utilizando el parámetro dtype para garantizar que los datos se importen correctamente.
También puedes necesitar realizar operaciones de limpieza inicial, como eliminar filas o columnas específicas que no son relevantes para tu análisis.
Por último, es importante tener en cuenta el rendimiento al importar grandes conjuntos de datos.
Pandas ofrece varias opciones para optimizar la importación de datos, como el uso de parámetros como chunksize para leer los datos en trozos más pequeños, lo que puede ser útil si estás trabajando con conjuntos de datos extremadamente grandes que no caben en la memoria RAM.
3. Eliminación de Valores Nulos
Al trabajar con conjuntos de datos reales, es común encontrarse con valores nulos o faltantes que pueden afectar la calidad de nuestro análisis.
La eliminación de estos valores es un paso crítico en el proceso de limpieza de datos y puede realizarse de varias formas con Pandas.
Una opción es eliminar todas las filas que contienen valores nulos utilizando el método dropna().
Esto es útil cuando la presencia de valores nulos es insignificante en comparación con el tamaño total del conjunto de datos.
Sin embargo, es importante tener en cuenta que esta estrategia puede resultar en la pérdida de una cantidad significativa de datos, por lo que se debe usar con precaución.
Otra opción es reemplazar los valores nulos con un valor específico utilizando el método fillna().
Esto puede ser útil cuando no queremos perder datos y preferimos asignar un valor específico, como cero o el valor medio de la columna, a los valores nulos.
Esto ayuda a mantener la integridad de nuestro conjunto de datos sin comprometer la calidad del análisis.
También es importante considerar el contexto de nuestros datos al eliminar los valores nulos.
Por ejemplo, si estamos realizando un análisis estadístico, la eliminación de valores nulos puede afectar la distribución de nuestros datos y sesgar nuestros resultados.
En tales casos, puede ser más apropiado imputar los valores nulos utilizando técnicas más avanzadas, como la interpolación o el uso de modelos predictivos.
4. Manipulación de Columnas
La manipulación de columnas es un aspecto fundamental del proceso de limpieza y preparación de datos en Python.
Pandas ofrece una variedad de métodos y funciones que facilitan esta tarea, permitiéndonos modificar y transformar nuestros datos según sea necesario.
Una de las operaciones más comunes que realizamos en las columnas es cambiarles el nombre para que sean más descriptivas y fáciles de entender.
Podemos hacer esto utilizando el método rename(), que nos permite especificar un nuevo nombre para una columna específica.
Esto es útil cuando queremos mejorar la claridad y la legibilidad de nuestros datos.
Además de cambiar los nombres de las columnas, a menudo necesitamos eliminar columnas que no son relevantes para nuestro análisis.
Esto se puede hacer fácilmente con el método drop(), que nos permite eliminar una o más columnas por su nombre.
Al eliminar columnas irrelevantes, podemos reducir el tamaño de nuestro conjunto de datos y centrarnos en las variables que son más importantes para nuestro análisis.
También es común que necesitemos agregar nuevas columnas a nuestro DataFrame basadas en cálculos o transformaciones de columnas existentes.
Por ejemplo, podemos calcular la suma o el promedio de varias columnas y almacenar el resultado en una nueva columna.
Pandas facilita esto con su sintaxis intuitiva y funciones como assign() y operadores aritméticos.
En resumen, la manipulación de columnas es una parte integral del proceso de limpieza y preparación de datos en Python.
Con Pandas, tenemos acceso a una amplia gama de herramientas que nos permiten cambiar nombres, eliminar columnas y agregar nuevas columnas según sea necesario, lo que nos brinda la flexibilidad y el control necesarios para preparar nuestros datos para el análisis.
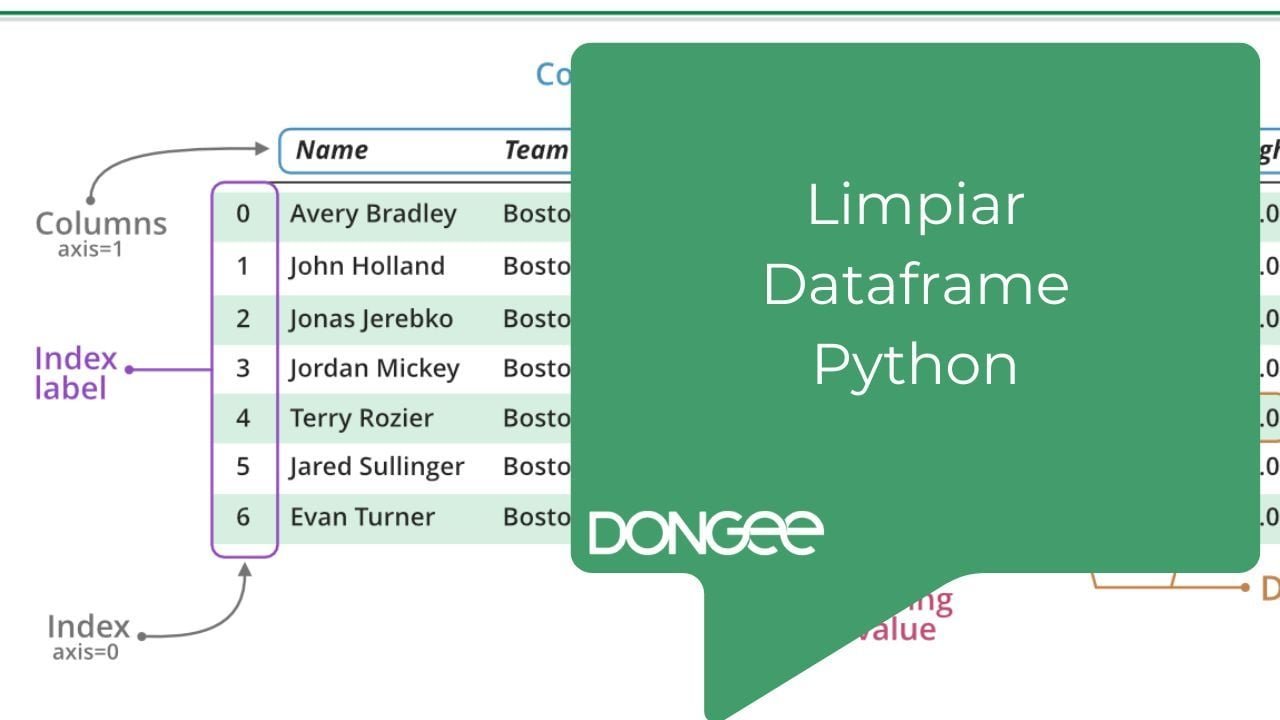
5. Gestión de Índices
La gestión de índices es una parte crucial de la manipulación de DataFrames en Pandas.
Los índices proporcionan etiquetas únicas para identificar filas o columnas en un DataFrame y facilitan operaciones como la selección, la alineación y la fusión de datos.
Aquí exploraremos algunas técnicas avanzadas para manejar índices en Pandas.
Una tarea común en la gestión de índices es restablecer el índice de un DataFrame.
Esto se puede hacer fácilmente con el método reset_index(), que convierte el índice actual en una columna y genera un nuevo índice numérico.
Esto es útil cuando queremos eliminar un índice existente o convertirlo en datos de columna para facilitar el análisis posterior.
Otra técnica útil es establecer un índice personalizado en un DataFrame utilizando el método set_index().
Esto nos permite seleccionar una o más columnas existentes como índice y utilizarlas para indexar el DataFrame.
Establecer un índice personalizado puede mejorar la eficiencia de ciertas operaciones, como la búsqueda y la fusión de datos, al permitir un acceso más rápido a los datos.
Además de restablecer y establecer índices, a menudo necesitamos reindexar un DataFrame para cambiar el orden de las filas o columnas.
Esto se puede hacer utilizando el método reindex() y especificando el nuevo orden deseado para el índice.
La reindexación es útil cuando queremos cambiar el orden de nuestras filas o columnas para que coincidan con un nuevo conjunto de etiquetas o índices.
Conclusión
En este exhaustivo tutorial, hemos explorado a fondo el proceso de limpieza de DataFrames en Python utilizando la potente biblioteca Pandas.
Desde la importación de datos hasta la manipulación de columnas y la gestión de índices, hemos abordado cada aspecto de este proceso esencial para garantizar que nuestros datos estén en su mejor forma antes de realizar cualquier análisis profundo.
A lo largo de nuestra exploración, hemos descubierto que la limpieza de datos es mucho más que una simple tarea de preparación: es un arte que requiere atención meticulosa a los detalles y un conocimiento profundo de las herramientas y técnicas disponibles.
Con Pandas a nuestro alcance, tenemos acceso a una amplia gama de funciones y métodos que facilitan enormemente este proceso, permitiéndonos manipular nuestros datos con precisión y eficiencia.
Sin embargo, también hemos aprendido que la limpieza de datos puede ser un desafío, especialmente cuando nos enfrentamos a conjuntos de datos complejos y desordenados.
En estos casos, es fundamental mantener una mente abierta y estar preparados para enfrentar obstáculos y superar errores en el camino.
Al final del día, la limpieza de DataFrames en Python es más que una tarea técnica: es un proceso creativo que nos permite descubrir información valiosa y obtener insights significativos de nuestros datos.
Con dedicación y práctica, podemos dominar esta habilidad y utilizarla para impulsar nuestros proyectos de análisis de datos y proyectos de ciencia de datos hacia el éxito.
Así que adelante, sumérgete en el mundo de la limpieza de datos con Python, y recuerda: ¡con las herramientas adecuadas y un enfoque metódico, no hay nada que no puedas lograr en el emocionante campo de la ciencia de datos!